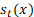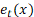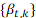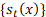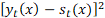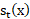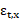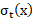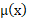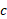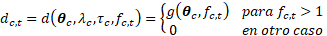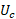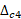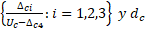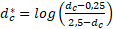Proyecciones probabilísticas de la fecundidad en Argentina
Fertility Probabilistic Projections in Argentina
Lucía Andreozzi
https://orcid.org/0000-0002-1723-5725
Instituto de Investigaciones Teóricas y Aplicadas de la Escuela de Estadística
Consejo Nacional de Investigaciones Científicas y Técnicas
Universidad Nacional de Rosario
Bruno Ribotta
https://orcid.org/0000-0003-1943-0513
Centro de Investigaciones y Estudios sobre Cultura y Sociedad
Consejo Nacional de Investigaciones Científicas y Técnicas
Universidad Nacional de Córdoba
Fecha de envío: 16 de junio de 2022. Fecha de dictamen: 9 de setiembre de 2022. Fecha de aceptación: 9 de setiembre de 2022.
Resumen
En los últimos años se ha propuesto una importante cantidad de métodos estadísticos demográficos. La gran mayoría han sido desarrollados con la finalidad de pronosticar las componentes demográficas y/o medidas derivadas a partir de la suposición de un modelo subyacente. El presente trabajo pretende realizar un ejercicio comparativo integral a través de la estimación y pronóstico de la fecundidad a partir de tres propuestas —métodos clásicos de pronóstico, tales como los modelos ARIMA y los suavizados exponenciales, modelos para datos funcionales (MDF) y modelos jerárquicos bayesianos (MJB)—, como un primer paso hacia el estudio de las proyecciones de población derivadas de cada una de ellas, empleando datos de la Argentina. El ejercicio tiene como horizonte final la estimación de la mortalidad y la fecundidad a través de los tres métodos mencionados para luego integrarlos en proyecciones de población.
Abstract
In recent years, a significant number of demographic statistical methods have been proposed. Most of them have been developed with the purpose of forecasting demographic components or indicators derived from the assumptions of an underlying model. The present work aims to carry out a comprehensive comparative exercise through the estimation and forecast of fertility based on three proposals —classic forecast methods such as ARIMA models and exponential smoothing, functional data models (FDM) and Bayesian hierarchical models (BHM)— as a first step towards the study of population projections derived from each of method, using data from Argentina. The exercise has as final objective the estimation of mortality and fertility through the three aforementioned methods to later integrate them into population projections.
Palabras clave: modelos para datos funcionales; modelos jerárquicos bayesianos; tasa global de fecundidad; Argentina; proyecciones demográficas.
Keywords: functional data models; Bayesian hierarchical models; global fertility rate; Argentina; demographic projections
Introducción
En los últimos años, se ha propuesto una importante cantidad de métodos estadísticos demográficos. La gran mayoría han sido desarrollados con la finalidad de pronosticar las componentes demográficas y/o medidas derivadas a partir de la suposición de un modelo subyacente. Sin embargo, es importante recordar que estos supuestos constituyen una representación acotada —por lo general, lo menos acotada posible— de una realidad compleja que finalmente es representada a través de múltiples formas funcionales y parámetros. Desde los clásicos suavizados exponenciales y modelos ARIMA de Box y Jenkins (1976) (del inglés, Autorregressive Integrated Moving Average), pasando por el modelo de Lee-Carter (Lee y Carter, 1992) y sus múltiples variantes hasta los modelos para datos funcionales propuestos por Hyndman y Booth (2008) y los modelos jerárquicos bayesianos propuestos por Alkema, Raftery, Gerland, Clark, Pelletier, Buettner y Heilig (2011), la gran gama de propuestas comprende modelos provenientes tanto del enfoque frecuentista como del bayesiano.
Entre las distintas alternativas se pueden encontrar propuestas que pretenden modelizar las componentes demográficas en forma aislada a través de formas funcionales simplificadas de su dinámica. De este modo permiten analizarla, estudiar tendencias, patrones de edad y sexo, para luego pronosticarlas.
Un caso particular de ellas es el modelo para datos funcionales (MDF), que además de modelizar las tres componentes (mortalidad, fecundidad y migraciones) por separado permite integrarlas en un único modelo de proyección de la población.
Una propuesta que se plantea como superadora son los modelos jerárquicos bayesianos (MJB), que constituyen un dispositivo complejo que, partiendo de la integración de información de múltiples niveles geográficos, modelan y pronostican la mortalidad y la fecundidad para luego integrarlas a una proyección de población. Este enfoque se presenta como superador al MDF, desarrollados principalmente para países de baja fecundidad que han atravesado la fase de transición y cuyo nivel de fecundidad fluctúa de un modo estable, estacionario. Sin embargo, más allá de la inclusión de tres fases en el modelado, el desarrollo teórico desemboca en la identificación de una forma funcional única o común que se adapta, mediante parámetros o restricciones, a casos particulares.
Finalmente, el método determinístico más clásico; el método de las componentes (en inglés, CCMPP: Cohort Component Method for Population Projections) resulta aún de una simplicidad y practicidad superlativa, más allá de su punto crítico más planteado: la imposibilidad de ofrecer intervalos de probabilidad asociada a los resultados.
Desde el punto de vista demográfico, la complejidad, tanto en la formulación del modelo como en su estimación, aumenta con cada nueva propuesta, al mismo tiempo que su capacidad para generar un retorno teórico disminuye, reduciéndolo a la mera producción de una cifra o de un par de cifras (intervalo) sin un análisis sociodemográfico que la/s contextualice.
El ejercicio tiene como horizonte final la estimación de la mortalidad y la fecundidad a través de los tres métodos mencionados para luego integrarlos en proyecciones de población. MDF y MJB incluyen, como última etapa de su implementación, la construcción de las proyecciones a partir de las componentes proyectadas. Sin embargo, para la integración de las propuestas más clásicas se plantea la construcción de las proyecciones de población a partir del método de las componentes basado en las estimaciones ARIMA/Suavizados.
Marco conceptual y antecedentes
La transición de la fecundidad. Uno de los principales modelos teóricos demográficos se refiere a la transición demográfica y constituye, en numerosas metodologías de pronóstico, el supuesto principal subyacente. La transición de la fecundidad puede definirse, a grandes rasgos, como el descenso a largo plazo en el número de hijos por mujer, de cuatro o más a dos o menos; sin embargo, esta simple definición deja de lado la idea del patrón de cambio bajo el cual se da ese descenso. En un ensayo publicado en Demography, Karen Oppenheim Mason (1997) aborda el tema de la transición de la fecundidad de manera exhaustiva, pero principalmente crítica: sostiene que es frecuente encontrar en la bibliografía demográfica la idea de transición como un todo, pero lo que resulta interesante es deconstruir la teoría en primer lugar con relación a su escala temporal; se la puede pensar en términos de milenios, siglos o décadas. Es en base a esta escala temporal que se estudia la correlación entre la fecundidad y los fenómenos o fuerzas que influyen en su dinámica, y son las escalas las que determinan las diferencias entre las regiones del mundo. Desde esta perspectiva, plantea seis grandes teorías sobre la fecundidad y postula cuatro grandes errores a la hora de analizarla. Las teorías:
* Thompson (1930) y Notestein (1953) atribuyen el descenso en la fecundidad a los cambios en la vida social, presuntamente atribuidos a la industrialización y la urbanización.
* Lesthaeghe (y Surkyn, 1988; y Wilson, 1986) agrega a los cambios económicos un cambio en los valores hacia el individualismo y la autorregulación asociados; pero su teoría describe claramente a Europa, no así a la mayoría de las otras regiones.
* Caldwell (1982) plantea una teoría de los flujos de riqueza intrafamiliar y la nuclearización de la familia y el apoyo entre generaciones como determinantes del descenso.
* Microeconómica clásica, que se basa en tres determinantes vinculados a las “elecciones” de parejas, costo de los hijos versus otros bienes de la pareja, pero nada agrega en relación con las condiciones ambientales e institucionales que afectan ingresos, costos y preferencias.
* Easterlin (1975 y 1978) y Easterlin y Crimmins (1985) agregan a la teoría anterior el concepto de “suministro de niños”, vinculada a la demanda y los costos de regulación de la fecundidad.
* Cleland y Wilson (1987) atribuyen “el ritmo” de la transición a la difusión de información y a las nuevas formas sociales sobre el control de la natalidad.
Según Oppenheim Mason (1997), estos serían los cuatro errores principales de estas teorías: primero, sostienen que todas las transiciones tienen la misma causa más allá del tiempo y del espacio, ignorando diferencias preexistentes en los patrones sociales y demográficos —ninguna proporciona una explicación completa de todas las disminuciones conocidas de la fecundidad—; segundo, ignoran el descenso en la mortalidad como precondición para el descenso en la fecundidad; tercero, suponen que la regulación de la fecundidad es fundamentalmente diferente entre las poblaciones pre-transicionales y pos-transicionales; cuarto, ponen el foco en una escala de décadas.
Es importante destacar que la teoría neoclásica proporciona un marco cuantificable para examinar el cambio de la fecundidad, pero como teoría ignora las condiciones ambientales e institucionales que modifican los costos, los ingresos y las preferencias, que también influyen en la disminución de la fecundidad. De la misma manera, el marco de la teoría de la oferta y la demanda contiene pocas ideas sobre los determinantes institucionales de la disminución de la fecundidad. Además, si bien intenta explicar cuándo se ha producido un cambio, no puede predecir de manera convincente por qué tales fenómenos no continúan ocurriendo en otras partes o regiones.
La fecundidad en Argentina y en América Latina. De acuerdo con el análisis de Chackiel y Schkolnik (2004), basado en estimaciones y proyecciones elaboradas conjuntamente por organismos nacionales y el Centro Latinoamericano de Demografía (CELADE), en América Latina, entre 1950-55 y 1985-90 se produjo un descenso importante de la fecundidad. Para el quinquenio 1950-55, Argentina y Cuba[1] presentaban una fecundidad media-baja y Uruguay una fecundidad baja, ubicándose entre los países con tasas globales de fecundidad más bajas de la región.
Tabla 1. América Latina, países según nivel de fecundidad 1950-1955 y 1985-1990
Nivel de fecundidad 1950-1955 | Nivel de fecundidad 1985-1990 | |||
Alta | Media alta | Media baja | Baja | |
Alta | Guatemala Honduras Nicaragua | Bolivia El Salvador Haití Paraguay | Brasil Costa Rica Ecuador México Panamá Perú Rep. Dominicana Venezuela | Colombia |
Media alta | Chile | |||
Media baja | Argentina Cuba | |||
Baja | Uruguay | |||
Fuente: Chackiel y Schkolnik (2004)
Particularmente, y como analiza Pantelides (1983), el caso de la transición de la fecundidad en la Argentina es interesante por haberse producido tempranamente en el contexto latinoamericano; la evolución de la mortalidad y la fecundidad se parece poco a la conocida forma “clásica” del modelo transicional. Esta clasificación permite identificar un subconjunto de países, que incluye a la Argentina, con comportamientos similares entre ellos, pero diferentes dentro de la región. Dicho conjunto se tendrá en cuenta en la etapa de modelización.
Objetivos
El primer paso: la fecundidad. El presente trabajo pretende realizar un ejercicio comparativo integral a través la estimación y pronóstico de la fecundidad a partir de tres propuestas: métodos clásicos de pronóstico, tales como los modelos ARIMA y los suavizados exponenciales; modelos para datos funcionales; y modelos jerárquicos bayesianos, lo que constituye un primer paso hacia el estudio de las proyecciones de población derivadas de cada una de ellas. Al referirse a la fecundidad, se resume la información en la tasa global de fecundidad (TGF), uno de los componentes claves en las proyecciones de población —el número promedio de hijos que una mujer dará a luz durante la etapa reproductiva—, experimentando en cada edad las tasas específicas de fecundidad de ese período y asumiendo la ausencia de mortalidad.
Datos y métodos
Las metodologías más clásicas para el modelado y pronóstico de datos correlacionados temporalmente son los modelos ARIMA y los suavizados exponenciales. Estas técnicas se consideran ampliamente difundidas y disponibles en la bibliografía de análisis de series temporales, es por ello que se explican a continuación los dos modelos más innovadores y se comentan los procedimientos seguidos en cada caso.
Modelo para datos funcionales
Se denota con la cantidad a ser modelada, tasas de mortalidad, fecundidad o números de migración neta para la edad en el año . Si bien es posible plantear una transformación general de Box y Cox (1964) sobre , que permite modelar una tasa cuya variación aumenta con el valor de , es decir, cuando la variabilidad de las tasas es mayor a medida que las tasas son mayores, en la mayoría de las aplicaciones se implementa directamente la transformación logaritmo.
Se supone el siguiente modelo para las observaciones transformadas
[1]
[2]
donde es una función suave subyacente de son variables aleatorias, independientes e idénticamente distribuidas, y la definición de permite a la variancia cambiar con la edad y con el tiempo. Esto significa que las observaciones transformadas son la suma de la cantidad a modelar, , una función suave de la edad y un error (primera ecuación). La segunda ecuación describe la dinámica de a través del tiempo: es la media de a través de los años; es un conjunto de K funciones base ortogonales calculadas utilizando una descomposición en componentes principales funcionales de la matriz ; y es el error del modelo (el cual se supone no correlacionado serialmente). La dinámica del proceso está controlada por los coeficientes , los cuales tienen un comportamiento independiente uno de otro (garantizado por la utilización del método estadístico de componentes principales).
Existen tres fuentes de variación en el modelo: representa la variación aleatoria con respecto a la distribución relevante para los nacimientos, muertes y migrantes (Poisson o Normal); representa el residuo que surge al modelar utilizando un conjunto de funciones bases; y además existe una aleatoriedad inherente al modelo de series de tiempo para cada que ejerce los cambios en la dinámica de la curva suave . Es importante destacar que es posible implementar este enfoque para edades simples y también para grupos quinquenales.
Este modelo fue propuesto inicialmente por Hyndman y Ullah (2007) para modelar tasas de mortalidad y fecundidad empleando una transformación logaritmo en lugar de plantear la transformación de Box-Cox. También ha sido utilizado por Erbas, Hyndman y Gertig (2007) para pronosticar tasas de mortalidad por cáncer de mama. Como señalan Hyndman y Ullah (2007), el modelo es una generalización del conocido modelo de Lee y Carter (1992) para pronosticar tasas de mortalidad. En el enfoque de Lee y Carter (1992), representa la tasa de mortalidad e es el logaritmo de la mortalidad para el año y la edad ; además, no incluye suavizados y por lo tanto e ; finalmente se estima como el promedio de a través de los años. El número de componentes y se obtienen a partir la primera componente principal de la matriz y los pronósticos se obtienen ajustando una serie de tiempo al coeficiente ; en la práctica el modelo que se obtiene resulta generalmente un paseo aleatorio con pendiente.
El modelo general que se aplica a cada una de las componentes demográficas se obtiene a través de las etapas que se enumeran a continuación:
1. Se estiman las funciones suaves a través de regresión no paramétrica sobre para cada año , ecuación (1);
2. A se la define como la media de a través de los años;
3. Los coeficientes y las bases , con se calculan aplicando análisis de componentes principales funcionales sobre la matriz ;
4. Se ajusta un modelo de series de tiempo a donde . Para ello es posible utilizar un modelo ARIMA (Box y Jenkins, 1976) o modelos de espacio de estado de innovaciones (Hyndman, Koehler, Ord y Snyder, 2008).
Aunque el valor de debe ser especificado, Hyndman y Ullah (2007) sostienen que el método es insensible al valor elegido siempre y cuando sea lo suficientemente grande. Esto significa que el costo al elegir grande es pequeño (más allá del tiempo computacional), mientras que seleccionar un pequeño puede producir menor exactitud en los pronósticos. Hyndman y Booth (2008) utilizan para todos los componentes demográficos; esta cantidad en general es mayor a la que cualquier componente demográfica requiere.
La variancia observacional depende de la naturaleza de los datos. Para las muertes, la variancia observacional se estima a partir del logaritmo de las tasas suponiendo que las muertes se distribuyen Poisson (Brillinger, 1986) con parámetro medio (donde es la población de edad expuesta al riesgo al 30 de junio del año ). Luego tiene una variancia aproximada y la variancia de (por aproximación de Taylor) resulta:
.
Para los nacimientos se supone una distribución Poisson (Keilman, Pham y Hetland, 2002) con media , lo que implica
[3]
Para los datos de migraciones no se hacen supuestos distribucionales y se estima utilizando una regresión no paramétrica de sobre .
Puntualmente, Hyndman y Ullah (2007) sugieren utilizar regresión spline penalizada con restricciones para las tasas de mortalidad y fecundidad, de modo que los pesos contemplen la heterogeneidad presente en este tipo de datos. Se impone además una restricción de monotonía para las tasas de mortalidad y una restricción de concavidad para las de fecundidad. Más específicamente, para datos de mortalidad, se definen pesos iguales a la inversa de la variancia teórica (derivada del supuesto distribucional Poisson) y se utiliza una regresión spline penalizada (Wood, 2003; y He y Ng, 1999), para estimar las curvas que representan a las tasas luego de la transformación logarítmica. La restricción impuesta determina que las curvas sean monótonamente crecientes para , es decir, a partir de una edad determinada, permitiendo reducir el ruido en las curvas estimadas para edades avanzadas. La imposición resulta lógica dado que cuanto más anciana es una persona tiene más probabilidad de morir.
Para los datos de fecundidad se utilizan los pesos de modo análogo y se impone como restricción la concavidad de las curvas, respetando el perfil observado habitualmente en las curvas de fecundidad. El método que permite implementar esta restricción puede verse en He y Ng (1999). Para suavizar las tasas de fecundidad se utiliza una regresión cuantil semiparamétrica por B-Splines con restricciones (He y Shi, 1996) que permite establecer restricciones a las funciones suavizadas, tales como monotonía, convexidad, concavidad o límites. Finalmente, para las migraciones se utiliza simplemente un suavizado por regresión local, loess.
Para el caso de las tasas de fecundidad, se detalla el enfoque de datos funcionales en demografía (Hyndman y Ullah, 2007; Hyndman y Booth, 2008). Para ello se definen los datos necesarios para estimar la fecundidad, donde:
: nacimientos en mujeres de edad x ocurridos durante el año calendario t,
: población de mujeres de edad expuesta al riesgo al 30 de junio del año ,
donde y. La tasa de fecundidad de la edad x en el año calendario t se define como:
[4]
En el siguiente modelo, se denota con a la cantidad a ser modelada, en este caso la fecundidad de la madre de edad en el año . Primero se plantea una transformación de Box-Cox de y luego se supone el siguiente modelo para la cantidad transformada :
[5]
, [6]
donde es una función suave subyacente de ; son variables aleatorias gaussianas, independientes e idénticamente distribuidas; y es la varianza que puede variar con la edad y con el tiempo. Es posible implementar el enfoque para años y edades simples, así como también para grupos quinquenales. Luego, es una función suave de la edad que se observa con error y describe la dinámica de a través del tiempo. En esta ecuación, es la media de a través de los años; es un conjunto de funciones base ortogonales calculadas utilizando una descomposición en componentes principales; es el error del modelo, el cual se supone no correlacionado serialmente. La dinámica del proceso está controlada por los coeficientes , los cuales tienen un comportamiento independiente uno de otro (por propiedades del método de componentes principales).
En este enfoque, representa la tasa de fecundidad y se fija el parámetro de la transformación de Box y Cox, . Por ello es el logaritmo de la fecundidad para el año t y la edad x. En el modelo de Lee-Carter, desarrollado para el análisis de la mortalidad, no se realiza ningún tipo de suavizado, por ello, y a se estima como el promedio de a través de los años. Para ,se obtiene a partir de la primera componente principal de la matriz . Los pronósticos se obtienen ajustando un modelo de serie de tiempo a ; en la práctica el modelo resulta generalmente un paseo aleatorio con pendiente, en esta etapa la selección se realiza automáticamente empleando el modelo que genera el menor valor del criterio de Akaike.
Modelo jerárquico bayesiano
El modelo de proyección bayesiano propuesto por Alkema y otros se basa en estimaciones quinquenales de la tasa global de fecundidad desde 1950-1955 hasta 2015-2020. Su implementación se encuentra disponible para su uso en R en el paquete bayesTFR (Sevcíková, Alkema y Raftery, 2008). Para ello se divide la evolución de la TGF en tres amplias fases:
I: una fase de alta fecundidad pre-transicional;
II: la transición a la fecundidad en la cual la TGF decrece desde niveles de fecundidad altos hacia o por debajo del nivel de fecundidad de reemplazo;
III: una fase posterior a la transición de baja fecundidad que incluye la recuperación de la fecundidad por debajo del reemplazo hacia la fecundidad de reemplazo y las oscilaciones alrededor de la fecundidad a ese mismo nivel.
El período de observación para cada país se divide en estas diferentes fases en función de las definiciones deterministas de sus períodos de inicio y finalización, y luego se modela por separado. Por tanto, se define como el comienzo de la fase II para el país c, la cual es dada por:
[7]
donde es el valor máximo de la TGF observada en el país , y indica el máximo local. El momento de inicio de la fase III para el país , indicado por , se encuentra dentro del período de datos observados si existen dos aumentos consecutivos de la TGF y a su vez esta es menor a 2.
[8]
donde es la TGF del país en el periodo . Para el resto de los países, .
En el MJB no se plantea un modelo para la fase I dado que se asume que en el siguiente periodo alcanzará la fase II y en base a ella se realizarán las proyecciones de la TGF. A continuación, se expone el modelo para la fase II.
Modelo para la fase II o transición de la fecundidad
Esta fase se modela mediante un paseo aleatorio con pendiente dado por
[9]
siendo la TGF para el período en el país ; es el decremento que representa la disminución sistemática de la fecundidad durante la transición; es el error aleatorio; y y los momentos de inicio y fin de la etapa de transición. La distribución del error está dada por
[10]
donde es la media y la desviación estándar en el momento inicial de la fase; y es la desviación para los restantes valores de t
[11]
siendo la desviación estándar máxima de los errores alcanzada en nivel S de la TGF y a y b son los multiplicadores de la desviación estándar para modelar la disminución lineal para valores más grandes y pequeños de la TGF. La constante se agrega para modelar la variancia del error más grande antes de 1975.
Finalmente se modela como función del nivel la TGF y el vector del siguiente modo;
[12]
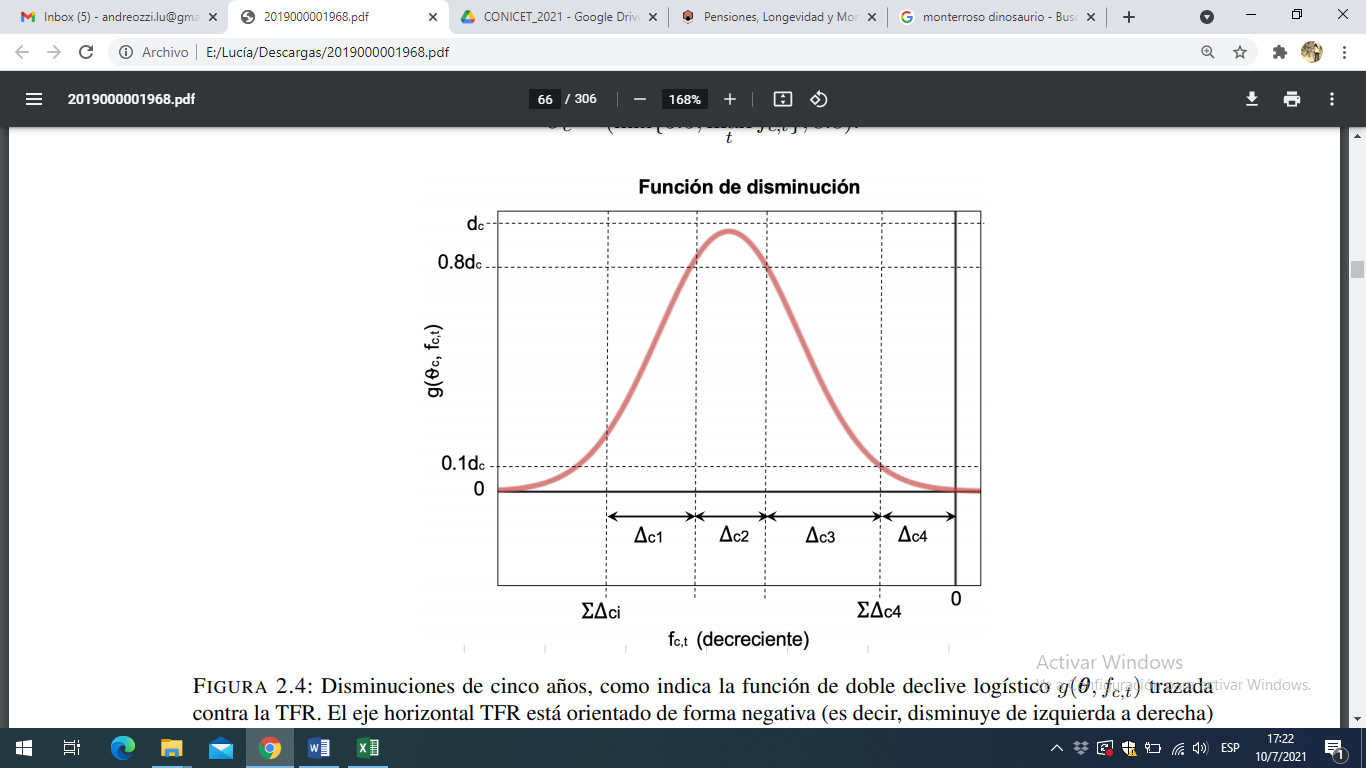
siendo una función de diminución paramétrica. La función de disminución es la suma de dos funciones logísticas, y para un país específico viene dada por
[13]
donde es el vector de parámetros específicos de un país; es la disminución máxima; son constantes y los describen los rangos de la TGF, entre los cuales el ritmo de la disminución cambia; y es el nivel de comienzo de la disminución de la fecundidad.
Se estiman para cada país los parámetros de disminución, y para los países en que el comienzo de la fase II está dentro del período de datos observados se fija igual al valor de la TGF de fecundidad en ese período, es decir, Para los países en los cuales la fase II se inició previo al periodo de observación el nivel de inicio se agrega como otro parámetro más del modelo.
Figura 1. Esquema de la función de disminución
Fuente: elaboración propia
Dado el nivel de comienzo, , los cinco parámetros que determinan el ritmo de la disminución de la fecundidad en el país son , , y se estiman a partir de un modelo jerárquico bayesiano dado por:
[14]
[15]
[16]
[17]
[18]
[19]
[20]
Con media y varianza de parámetros .
Las proyecciones de la TGF para los países en fase II se basan en la distribución posterior de los parámetros del modelo y la mediana se emplea como valor de proyección dada su robustez y simplicidad.
En la fase III o de postransición, el cambio en la TGF se modela a través de un proceso AR(1) con media , que es una aproximación de la TGF para la fecundidad a nivel de reemplazo.
(21)
donde es el parámetro autorregresivo, con , y la desviación estándar de los errores aleatorios, que se estiman a través de máxima verosimilitud.
En síntesis, para la proyección de la TGF a través del modelo jerárquico bayesiano se procede al ajuste del modelo; se calculan o estiman los momentos de inicio de las fases II y III para cada país; luego, se obtiene una muestra a posteriori de los parámetros del modelo mediante el algoritmo MCMC (Markov chain Monte Carlo) para, finalmente, generar a partir de ella las trayectorias futuras de la TGF. Los autores puntualizan que la mediana, y no la media, se emplea como la mejor proyección dada su clara interpretación y robustez en relación con el comportamiento de las colas de las distribuciones posteriores, independientemente de la forma de la distribución posterior: la mitad de las trayectorias de la TGF está arriba, y la mitad de las trayectorias está por debajo de la mediana.
Fuentes
Existe una relativa escasez y fragmentariedad de los datos cuantitativos disponibles para la investigación histórica y sus tendencias, hecho que reduce las posibilidades de su explotación. La información que se emplea para las proyecciones demográficas se basa generalmente en datos secundarios publicados con aproximaciones predominantemente demográficas.
Con relación a las dos propuestas metodológicas que se analizan en el presente estudio, Alkema et al. (2011) se basa en los datos de World Population Prospects, para quien, de acuerdo con los metadatos disponibles en el sitio, las cifras de fecundidad se calculan en base a:
* Nacimientos registrados clasificados por edad de la madre y la población femenina subyacente por edad hasta 2016, ajustados por subregistro;
* Nacimientos en el hogar en los 12 (o 24) meses anteriores clasificados por edad de la madre de los censos de 1947, 1960, 1970, 1980, 1991, 2001, 2010 y MICS 2011-2012;
* Fecundidad ajustada utilizando el método de la relación P/F de Brass (o variantes) con datos sobre los niños nacidos vivos y los nacimientos en los 12 (o 24/36) meses anteriores, ambos clasificados por edad de la madre, desde 1947, 1960, 1970;
* Censos de 1980, 1991, 2001, 2010 y MICS 2011-2012;
* Estimaciones indirectas obtenidas de la aplicación del método inverso de supervivencia a los censos de 1980, 1991;
* Estimaciones internacionales consideradas hasta 2017;
* Estimaciones oficiales de las tasas de fecundidad específicas por edad hasta 2017.
Por otro lado, los modelos para datos funcionales se aplican a tasas de mortalidad y fecundidad. Para ello, los datos requeridos son los nacimientos según edad de la madre y la población por grupo quinquenal. Es importante destacar que durante la estimación es necesario contar con las cantidades netas tanto de eventos como de población. Por ello no es la tasa en sí el dato base, sino que se lo construye a partir de los registros de nacimientos y las cifras de población. Con relación a los datos provenientes del registro de hechos vitales, son suministrados por la Dirección de Estadísticas e Información de Salud (DEIS), a través de bases de datos que contienen el registro de los hechos individuales que permiten generar la matriz por grupos de edad para un período de tiempo de aproximadamente 30 años. En cambio, con relación a las cifras de población se decide utilizar la población por grupos quinquenales disponible en la página web de la Comisión Económica para América Latina y el Caribe (CEPAL).
Resultados
Se presentan las estimaciones obtenidas para la TGF desde 2015 a 2095 mediante los distintos enfoques. Las técnicas clásicas poseen particularidades: los modelos ARIMA requieren un mínimo de datos observados de manera que sean suficientes para la estimación de los parámetros; la técnica de suavizado exponencial de Holt no resulta tan estricta frente a este requisito, de modo que es más aplicable a series temporales más reducidas (breves). Luego, cuando los datos se presentan para períodos de cinco años calendario se cuenta tan solo con 6 datos para el periodo 1980-2010, pero en cambio se dispone de 30 datos si se consideran datos anuales. Se excluye el modelo ARIMA dado que presenta resultados incongruentes: cuando se estima el modelo en base a la serie de 30 datos, presenta una tendencia decreciente demasiado abrupta y poco compatible con la realidad.
La tabla 2 incluye las estimaciones del MJB para distintos períodos de base. En primer lugar, dado que los datos de estadísticas vitales presentan una calidad alta desde 1980 en adelante, se evalúan los modelos excluyendo períodos anteriores. En segundo lugar, se excluyen períodos para los cuales la TGF de fecundidad se calcula en base a proyecciones de población, es decir se combinan distintos inicios del período de datos observados con una finalización en 2010. Finalmente, se estima el modelo con la serie completa disponible en la web de World Population Prospects 2019 (United Nations, 2019).
Tabla 2. Pronósticos de la Tasa Global de Fecundidad obtenidos mediante el modelo jerárquico bayesiano (2015-2095)
Período de pronóstico | Período empleado para la estimación | |||||||
1950-2010 | 1955-2010 | 1960-2010 | 1965-2010 | 1970-2010 | 1975-2010 | 1980-2010 | 1950-2015 | |
2015-2020 | 2,21 | 2,21 | 2,22 | 2,22 | 2,21 | 2,19 | 2,19 | 2,27 |
2020-2025 | 2,13 | 2,13 | 2,15 | 2,16 | 2,14 | 2,10 | 2,10 | 2,20 |
2025-2030 | 2,07 | 2,06 | 2,07 | 2,08 | 2,09 | 2,02 | 2,02 | 2,14 |
2030-2035 | 2,00 | 2,00 | 2,01 | 2,02 | 2,05 | 1,96 | 1,97 | 2,07 |
2035-2040 | 1,96 | 1,95 | 1,96 | 1,97 | 2,02 | 1,91 | 1,92 | 2,01 |
2040-2045 | 1,92 | 1,91 | 1,92 | 1,94 | 1,98 | 1,87 | 1,88 | 1,97 |
2045-2050 | 1,88 | 1,89 | 1,90 | 1,90 | 1,96 | 1,85 | 1,85 | 1,93 |
2050-2055 | 1,86 | 1,86 | 1,87 | 1,88 | 1,95 | 1,83 | 1,83 | 1,89 |
2055-2060 | 1,84 | 1,85 | 1,86 | 1,86 | 1,94 | 1,83 | 1,82 | 1,86 |
2060-2065 | 1,83 | 1,83 | 1,85 | 1,85 | 1,94 | 1,81 | 1,82 | 1,84 |
2065-2070 | 1,83 | 1,83 | 1,84 | 1,85 | 1,94 | 1,81 | 1,81 | 1,82 |
2070-2075 | 1,83 | 1,82 | 1,84 | 1,84 | 1,94 | 1,80 | 1,81 | 1,80 |
2075-2080 | 1,82 | 1,83 | 1,84 | 1,84 | 1,94 | 1,81 | 1,81 | 1,79 |
2080-2085 | 1,82 | 1,82 | 1,84 | 1,84 | 1,94 | 1,81 | 1,81 | 1,79 |
2085-2090 | 1,82 | 1,82 | 1,84 | 1,84 | 1,95 | 1,82 | 1,81 | 1,79 |
2090-2095 | 1,82 | 1,83 | 1,84 | 1,84 | 1,95 | 1,82 | 1,82 | 1,77 |
Fuente: Elaboración propia en base a datos de World Population Prospects 2019.
Por otro lado, se presentan las proyecciones basadas en el MDF y datos de 1980 a 2010 (tabla 3). La estimación del modelo de pronóstico se basa en datos de fecundidad por grupos etarios, es decir las tasas de fecundidad específicas, a diferencia del MJB que se fundamenta en series de la TGF. En la misma tabla se presentan las proyecciones a través de la técnica de suavizado exponencial de Holt para tres series: TGF para períodos quinquenales de 1950 a 2010, para 1950 a 2015, y el periodo 1980-2010 pero para la serie anual.
Tabla 3. Pronósticos de la Tasa Global de Fecundidad obtenidos mediante el modelo para datos funcionales y técnicas de suavizado exponencial de Holt (2015-2095)
Período de pronóstico | Modelo/Técnica | |||
FDM 1980-2010 | Holt 1950-2010 (quinquenal) | Holt 1950-2015 (quinquenal) | Holt 1980-2010 (anual) | |
2015-2020 | 2,26 | 2,17 | 2,12 | 2,31 |
2020-2025 | 2,18 | 2,08 | 2,05 | 2,28 |
2025-2030 | 2,10 | 2,00 | 1,87 | 2,25 |
2030-2035 | 2,03 | 1,92 | 1,90 | 2,23 |
2035-2040 | 1,96 | 1,84 | 1,82 | 2,20 |
2040-2045 | 1,89 | 1,76 | 1,74 | 2,18 |
2045-2050 | 1,83 | 1,67 | 1,67 | 2,15 |
2050-2055 | 1,77 | 1,59 | 1,60 | 2,12 |
2055-2060 | 1,71 | 1,43 | 1,52 | 2,10 |
2060-2065 | 1,66 | 1,35 | 1,45 | 2,07 |
2065-2070 | 1,61 | 1,26 | 1,38 | 2,05 |
2070-2075 | 1,55 | 1,18 | 1,30 | 2,02 |
2075-2080 | 1,51 | 1,10 | 1,22 | 1,99 |
2080-2085 | 1,46 | 1,02 | 1,15 | 1,97 |
2085-2090 | 1,42 | 0,94 | 1,08 | 1,94 |
2090-2095 | 1,37 | 0,85 | 1,00 | 1,92 |
Fuente: Elaboración propia en base a datos de World Population Prospects 2019.
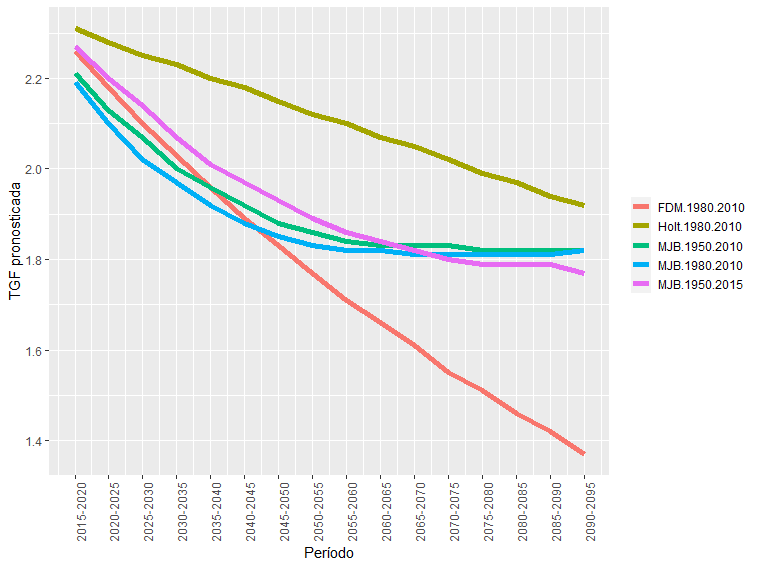
De las series de pronósticos, es interesante evaluar el nivel al inicio del período de pronóstico, al final y el momento o período en el cual se da la caída por debajo del nivel de reemplazo. Teniendo en cuenta que oficialmente el Instituto Nacional de Estadísticas y Censos de la Argentina (Indec, 2013) ubica la TGF estimada para 2020 en torno a los 2,2 hijos por mujer, de los modelos jerárquicos, los estimados en base a los períodos 1980-2010 y 1950-2015 se encuentran cercanos a dicho valor. En relación también al inicio de los pronósticos, los valores del FDM y el MJB 1950-2015 presentan valores similares y cercanos a 2,3. Sin embargo, la mayor divergencia se presenta en el patrón y en la tendencia: solo los MJB muestran una desaceleración en el ritmo de disminución, y los pronósticos hacia el final del período de pronóstico, por ejemplo, para el período 2090-2095, presentan grandes diferencias según el método de estimación, más allá de ubicarse todos por debajo del nivel de reemplazo. En este aspecto, resulta interesante destacar que el suavizado de Holt estimado bajo el período 1980-2010 (serie anual) presenta uno de los valores más altos —1,92 hijos por mujer—, en concordancia con el pronóstico por MJB estimado en base al período 1970-2010, cuyo valor resulta de 1,95 hijos por mujer. A continuación, en la figura 2, se presentan los pronósticos seleccionados en base a la coherencia en los valores iniciales y finales de los pronósticos estimados, con el fin de visualizar el patrón de cada una de las series.
Figura 2. Pronósticos 2015-2095, seleccionados para la comparación: modelo jerárquico bayesiano 1980-2010, 1950-2015; modelo para datos funcionales 1980-2010; y suavizado de Holt 1980-2010.
Fuente: Elaboración propia en base a datos de World Population Prospects 2019.
En una segunda etapa, y en base a lo desarrollado sobre la fecundidad en América Latina, se estiman varios MJB (tabla 4.) sobre el subgrupo de países compuesto por Argentina, Colombia, Chile, Cuba y Uruguay, para los períodos que presentaron resultados más plausibles usando el MJB general, con datos a nivel mundial.
Tabla 4. Pronósticos de la Tasa Global de Fecundidad obtenidos mediante el MJB supuesto basado en el análisis de Chackiel.
Período | MJB – Supuesto de Chackiel | ||
1950-2010 | 1980-2010 | 1980-2015 | |
2015-2020 | 2,20 | 2,18 | 2,27 |
2020-2025 | 2,12 | 2,09 | 2,19 |
2025-2030 | 2,05 | 2,02 | 2,12 |
2030-2035 | 1,99 | 1,95 | 2,05 |
2035-2040 | 1,93 | 1,89 | 2,00 |
2040-2045 | 1,89 | 1,85 | 1,94 |
2045-2050 | 1,86 | 1,81 | 1,90 |
2050-2055 | 1,83 | 1,78 | 1,86 |
2055-2060 | 1,81 | 1,77 | 1,84 |
2060-2065 | 1,80 | 1,76 | 1,82 |
2065-2070 | 1,79 | 1,75 | 1,81 |
2070-2075 | 1,78 | 1,75 | 1,82 |
2075-2080 | 1,78 | 1,76 | 1,81 |
2080-2085 | 1,80 | 1,77 | 1,82 |
2085-2090 | 1,81 | 1,80 | 1,83 |
2090-2095 | 1,83 | 1,82 | 1,84 |
Fuente: Elaboración propia en base a datos de World Population Prospects 2019.
A continuación, se presentan los resultados gráficamente en la figura 3. Allí se observa la divergencia en los pronósticos iniciales y cómo el MJB-CH estimado 1980-2010 se separa del resto de las tendencias.
Para evaluar la bondad de ajuste de los diferentes modelos propuestos y hacer una comparación se calcula la cobertura, es decir, la proporción de datos observados ajustados dentro de los intervalos de probabilidad dados de la distribución posterior predictiva de la función logística doble, así como la raíz del error cuadrático medio de la simulación. Nuevamente se destaca el MJB-CH 1980-2010 con un comportamiento diferente.
Figura 3. Pronósticos 2015-2095, seleccionados para la comparación: modelo jerárquico bayesiano estimado en base a la selección de países de baja fecundidad en el período inicial.
Fuente: Elaboración propia en base a datos de World Population Prospects 2019.
Tabla 5. Cobertura y error cuadrático medio de los modelos estimados.
Modelo | Cobertura | RECM |
MJB 1950-2010 | 0,909 | 0,231 |
MJB 1955-2010 | 0,900 | 0,224 |
MJB 1960-2010 | 0,889 | 0,228 |
MJB 1965-2010 | 0,889 | 0,228 |
MJB 1970-2010 | 0,857 | 0,207 |
MJB 1975-2010 | 1 | 0,197 |
MJB 1980-2010 | 1 | 0,211 |
MJB 1950-2015 | 0,923 | 0,217 |
MJB Chackiel 1950-2010 | 0,909 | 0,280 |
MJB Chackiel 1980-2010 | 1 | 0,098 |
MJB Chackiel 1950-2015 | 0,923 | 0,259 |
Fuente: Elaboración propia en base a datos de World Population Prospects 2019
Conclusiones
Sobre los resultados aquí presentados, vinculados a diversos períodos de estimación, modelos y conjuntos de datos base, es posible decir que los MJB generan pronósticos con una forma funcional plausible. Y si bien podría mejorar el ajuste trabajar con un subconjunto de países con patrones o historias de fecundidad más similares, las diferencias que se observan no son significativas desde un punto de vista demográfico, por lo que es importante repensar el binomio complejidad y exactitud.
Como ya se enunció, los MDF fueron desarrollados principalmente para países de baja fecundidad que han atravesado la fase de transición y cuyo nivel de fecundidad fluctúa de un modo estable. Particularmente, en el caso de los MJB, en base a una cuantificación de la teoría de la transición de la fecundidad, se estiman curvas que modelizan al mismo tiempo los datos mundiales y de cada país basándose en la estimación de alrededor de 14 hiperparámetros bayesianos. La sobreabundancia de estrategias abre un panorama infinito de comparaciones, ligadas a las fuentes de datos de entrada, la elección de periodos de estimación y las formas funcionales impuestas.
Complementando estos resultados, es necesario evaluar los intervalos de pronóstico que cada estrategia brinda, sus amplitudes y propiedades. Este ejercicio comparativo pretende ser el inicio de ese camino, pero de algún modo también trae algo de luz y simplicidad frente a la gran cantidad de series de pronósticos que es posible generar.
Referencias bibliográficas
ALKEMA, Leontine; RAFTERY, Adrian E.; GERLAND, Patrick; CLARK, Samuel J.; PELLETIER, François; BUETTNER, Thomas; y HEILIG, Gerhard K. (2011). “Probabilistic projections of the total fertility rate for all countries”. Demography, 48-3, 815-839.
BOX, George E. P. y COX, David R. (1964). “An analysis of transformations”. Journal of the Royal Statistical Society. Series B (Methodological), 26-2, 211-252.
BOX, George E. P. y JENKINS, Gwilym M. (1976). Time Series Analysis: Forecasting and Control. San Francisco: HoldenDay.
BRILLINGER, David R. (1986). “The natural variability of vital rates and associated statistics”. Biometrics, 42, 693-734.
CALDWELL, John C. (1982). Theory of Fertility Decline. London: Academic Press.
CHACKIEL, Juan y SCHKOLNIK, Susana. (2004). América Latina: los sectores rezagados en la transición de la fecundidad. En AA. VV., La fecundidad en América Latina. ¿Transición o revolución?, pp. 51-73. Santiago de Chile: Cepal.
CLELAND, John y WILSON, Christopher. (1987). “Demand Theories of the Fertility Transition: An Iconoclastic View”. Population Studies, 41-1, 5-30.
CEPAL (Comisión Económica para América Latina y el Caribe). (2021). Estimaciones y proyecciones: archivos excel. Disponible en: https://www.cepal.org/es/temas/proyecciones-demograficas/estimaciones-proyecciones-excel [consulta: 10 de enero de 2021].
EASTERLIN, Robert A. (1975). “An Economic Framework for Fertility Analysis”. Studies in Family Planning, 6, 54-63.
EASTERLIN, Richard A. (1978). The Economics and Sociology of Fertility: A Synthesis. En C. Tilly (ed.), Historical Studies of Changing Fertility, pp. 57-133. Princeton: Princeton University Press.
EASTERLIN, Richard A. y CRIMMINS, Eileen N. (1985). The Fertility Revolution: A Demand-Supply Analysis. Chicago: University of Chicago Press.
ERBAS, Bircan; HYNDMAN, Rob; y GERTIG, Dorota. (2007). “Forecasting age-specific breast cancer mortality using functional data models”. Statistics in Medicine, 2-26, 458-470.
HE, Xuming y NG, Pin. (1999). “Cobs: qualitatively constrained smoothing via linear programming”. Computational Statistics, 14, 315-337.
HE, Xuming y SHI, Peide. (1996). “Monotone b spline smoothing.” Journal of the American Statistical Asociation, 93, 643-650.
HYNDMAN, Rob y BOOTH, Heather. (2008): “Stochastic Population Forecasting Using Functional Data Models for Mortality, Fertility and Migration”. International Journal of Forecasting, 24,323-342.
HYNDMAN, Rob; KOEHLER, Anne; ORD, Keith; y SNYDER, Ralph. (2008). Forecasting with Exponential Smoothing: The State Space Approach. Heidelberg: Springer.
HYNDMAN, Rob y ULLAH, Shahid M. (2007). “Robust forecasting of mortality and fertility rates: A functional data approach”. Computational Statistics and Data Analysis, 51, 4.942- 4.956.
INDEC (Instituto Nacional de Estadísticas y Censos). (2013). Estimaciones y proyecciones de población 2010-2040. Total del país. Buenos Aires: Autor. Disponible en: https://www.indec.gob.ar/ftp/cuadros/publicaciones/proyeccionesyestimaciones_nac_2010_2040.pdf [consulta: noviembre de 2022].
KEILMAN, Nico; PHAM, Dinh Q.; y HETLAND, Arve. (2002). “Why population forecasts should be probabilistic - illustrated by the case of Norway”. Demographic Research, 6-15, 409-454.
LEE, Ronald D. y CARTER, Lawrence R. (1992). “Modeling and Forecasting U. S. Mortality”. Journal of the American Statistical Association, 87-419, 659-671.
LESTHAEGHE, Ron y SURKYN, Johan. (1988). “Cultural Dynamics and Economic Theories of Fertility Change”. Population and Development Review, 14-1, 1-45.
LESTHAEGHE, Ron y WILSON, Chris. (1986). Modes of Production, Secularization, and the Pace of the Fertility Decline in Western Europe, 1870-1930. En Ansley J. Coale y Susan C. Watkins (eds.), The Decline of Fertility in Europe, pp. 261-292. Princeton: Princeton University Press.
OPPENHEIM MASON, Karen. (1997). “Explaining Fertility Transitions”. Demography, 34-4, pp. 443-454. Disponible en: https://www.jstor.org/stable/3038299 [consulta: noviembre de 2022].
NOTESTEIN, F. (1953). “Economic Problems of Population Change”. Proceedings of the Eight International Conference of Agricultural Economics, pp. 13-31. London: Oxford University Press.
PANTELIDES, Edith A. (1983). La transición demográfica argentina: un modelo no ortodoxo. Buenos Aires: CENEP.
SEVCÍKOVÁ, Hana; ALKEMA, Leontine y RAFTERY, Adrian E. (2008). BayesTFR: Bayesian Fertility Projection, R package version 6.2. Disponible en: https://cran.r-project.org/web/packages/bayesTFR/bayesTFR.pdf [consulta 30 de junio de 2021].
THOMPSON, Warren S. (1930). Population Problems. New York: McGraw-Hill.
UNITED NATIONS. (2019). World Population Prospects. The 2019 Revision. Disponible en: https://population.un.org/wpp [consulta: 30 de junio de 2020].
WOOD, Simon. (2003). “Thin plate regression splines”. Journal of the Royal Statistical Society, 65-1, 95-114.
[1]Notas
Los rangos de variación son: baja, hasta 3 hijos por mujer; media baja, de 3.1 a 4.4; media alta, de 4.5 a 5.4; y alta, de 5.5 y más. Cabe mencionar, sin embargo, que estos límites son arbitrarios y la asignación de los países a cada uno de los grupos puede ser flexible.